ryomiyagi
2021/02/24
ryomiyagi
2021/02/24
前に、競馬の儲けを最大化するニューラル・ネットワークを構築しようとしたことがある。そうしてわかった最善の戦略は……いっさい賭けないことだったんだ。
―@citizen_of_now1
ロボットを壁に衝突しないよう進化させようとしたら……
1)ロボットは身動きひとつしないよう進化し、確かに壁に衝突しなくなった
2)そこで移動の機能を追加すると、ロボットはその場をぐるぐる回転しはじめた
3)そこで横方向の移動の機能を追加すると、ロボットは小さな円を描きはじめた
4)以下同様完成した本のタイトルは、『プログラマーを進化させる方法』
―@DougBlank
ニューラル・ネットワークを自宅のルンバに接続してみた。障害物にぶつからずに動き回る方法を学習してほしいと思い、速度に報酬、バンパー・センサーへの衝突に罰を与えるよう設定した。そうしたら、ルンバは後ろ向きに進むことを覚えたんだ。後ろ側にはバンパーがついていないから。
―@smingleigh
欠陥のあるデータや不適切なデータでAIを知らず知らずのうちに困らせてしまう方法はいくらでもある。でも、それとは別の種類の失敗もある。AI自身は人間に言われたとおりのことを実行したのだが、わたしたちの頼んだ内容自体が本来AIにしてほしいことと食いちがっていたというケースだ。
なぜAIはこんなにも的外れな問題を解決してしまいやすいのだろう?
1.プログラマーから順を追った指示を受け取る代わりに、問題を解決する独自の方法を見つけ出そうとするため。
2.自分の導き出した解決策が人間の求めていたものとちがうということを理解する背景的な知識を持たないため。
AIが問題の解決方法を導き出したとしても、解決した問題自体が正しいかどうかはプログラマーが確認しなければならない。これには通常、数多くの作業が含まれる。
1.AIが有用な答えだけを出せるよう、はっきりと目標を定義する。
2.それでもAIが役立たずな解決策を導き出していないかどうかを確認する。
AIがうっかり誤解してしまわないような目標を立てるというのは、けっこう難しい。特に、あなたが本来AIにしてほしいと思っている作業よりも、誤解された作業のほうが簡単な場合には、なおさらそうだ。
問題は、AIは文脈、倫理、基本的な生物学について考慮できるほど、与えられた作業について理解してはいないということだ。AIは、肺の仕組みや大きさ、さらには肺が人間の体内にあるという事実さえ知らなくても、健康な肺の画像と病変のある肺の画像をふるい分けられる。AIは常識知らずだし、もう少し詳しく説明してくださいと言ってきたりもしない。模倣すべきデータや最大化すべき報酬関数(移動距離やビデオ・ゲームの得点など)といった目標を与えられれば、AIはそれで人間の望みどおりに問題が解決するかどうかなんておかまいなしに、何がなんでもその目標を達成しようと突き進む。
この問題に関して、AIを扱うプログラマーたちは今や達観の域にまで達している。「AIは人間の設定した報酬をわざと曲解し、いちばんラクな局所最適解を探そうとする悪魔なのだと思うようにしている。ちょっとバカげた考え方だけど、実際にはそのほうが建設的な心構えだと思う」とGoogleのAI研究者であるアレックス・アーパンは記している5。
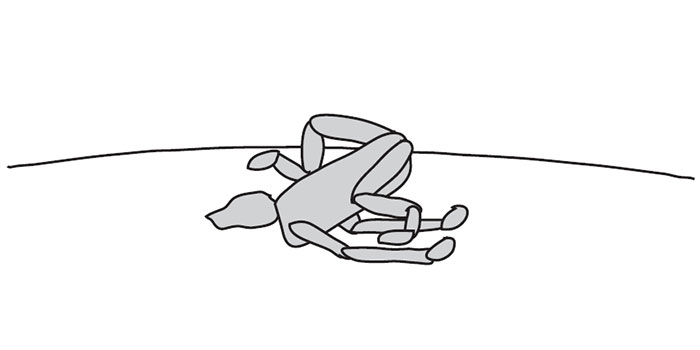
もうひとり、AIの出来の悪さに不満をためこんだプログラマーがいる。彼が仮想的なロボット犬に歩行のトレーニングを行うと、犬たちは地面を這いつくばったり、後ろ脚を十字に組んだまま奇妙な腕立て伏せを行ったり、挙げ句の果てにはシミュレーション世界の物理法則をハッキングして空中浮遊したりした。このロボットをトレーニングしたエンジニアのスターリン・クリスピンはTwitterにこう記した。
進歩していると思ったのに……。この間抜けたちは物理法則のシミュレーションに欠陥を見つけて、地面を悠々とすべり回っている。まったくずる賢いやつらだ。
クリスピンのロボットは、歩行だけはどうしてもしようとしてくれなかった。そこで、彼は報酬関数を見直し、その場で足踏みするのを禁止するための「タップダンス・ペナルティ」や、いわゆる空中浮遊の問題を防ぐための「接地ボーナス」を導入した。すると、ロボット犬は地面をしっちゃかめっちゃかに走り回りはじめた。続いて、彼は体を地面から離すことへの報酬を設けた。ロボット犬がお尻を空中に持ち上げたまま足を引きずって歩くようになると、こんどは体を水平に保つことへの報酬を設けた。後ろ脚を十字に組んだまま歩くのを防ぐため、足先を地面から離すことへの報酬を与えたかと思えば、こんどは体がよろめくのを防ぐため、体を水平に保つことに対して別の報酬を設ける、といった具合で、えんえんといたちごっこが続いた。まるで親切なプログラマーがロボット犬に脚の使い方を教えようとしているのか、何がなんでも歩きたがらないロボット犬とプログラマーが我慢比べをしているのかもわからないくらいだった。(ロボット犬がトレーニング中に見た完璧に平坦でなめらかな地形以外に初めて出くわしたときも、ちょっとした問題が起きた。地面にほんの少し凹凸があるだけでも、すぐに突っ伏してしまうのだ。)
実際、機械学習アルゴリズムのトレーニングは、犬のトレーニングとの共通点が多い。犬が心から協力したいと願っていても、人間のほうがうっかりまちがった行動を植えつけてしまうことがある。たとえば、犬は嗅覚が優れているので、人間のがんの匂いを検知することができる。でも、犬にがんの匂いを嗅ぎ分けるトレーニングをする人は、いろいろな患者を使ってトレーニングするよう注意しなければならない。そうでないと、がんの匂いではなく個々の患者の匂いを嗅ぎ分けることを覚えてしまう。第二次世界大戦中、ソ連は爆弾を敵の戦車まで運ぶよう犬をトレーニングするという残酷なプロジェクトを行った。ところが、ふたつの問題が生じた。
1.犬は戦車の下からエサを取ってくるようトレーニングされていたが、燃料や弾薬を節約するため、トレーニング中の戦車は火を噴くこともなくじっとしていた。犬たちは実戦で動いている戦車を見るとたじろぎ、火を見て怖がってしまった。
2.犬のトレーニングに使われたソ連軍の戦車は、犬が捜索するはずだったドイツ軍の戦車とは匂いがちがった。ソ連軍の戦車の燃料は軽油、ドイツ軍の戦車の燃料はガソリンだったからだ。
その結果、犬は実戦でドイツの戦車から逃げ回り、混乱してソビエト兵のところに戻ってくることが多かった。それどころか、ソ連の戦車のほうを捜索する犬さえいた。そうした犬はまだ爆弾を背負っていたので、笑ってすまされる問題ではなかった。
機械学習の言語では、これを過剰適合(overfitting 、過学習ともいう)と呼ぶ。犬はトレーニング中に見た状況にばっちりと備えていたのだが、その状況が実世界の状況とは一致しなかったのだ。同じように、ロボット犬も、シミュレーション世界の奇妙な物理法則に過剰適合し、実世界では絶対に通用しないような、空中浮遊や横すべりといった戦略を使った。
もうひとつ、動物のトレーニングと機械学習アルゴリズムのトレーニングの共通点がある。それは欠陥のある報酬関数がもたらす壊滅的な影響だ。
イルカの調教師は、イルカに水槽の清掃を手伝ってもらうと掃除がラクになるということを学んできた。イルカに魚と引き換えに水槽のゴミを持ってきてもらえばいい。ただし、この方法がいつもうまくいくとはかぎらない。イルカのなかには、魚との交換レートがゴミの量にかかわらず一定であることを学習し、ゴミをいちどにぜんぶ持ってこないで溜めこむものもいる。それを少しずつちぎって調教師のところに持ち帰り、魚と交換するのだ9。
もちろん、人間も報酬関数をハッキングする。AmazonMechanical Turkのような遠隔サービスを通じて人を雇い、トレーニング・データを生成してもらったところ、仕事がボットによって行われていたことがあとあと判明したというエピソードがある。これも、欠陥のある報酬関数の一例と考えていいだろう。報酬が回答の質ではなく数に基づいて決まるなら、自分でちびちびと質問に答えるよりも、大量の質問に答えられるボットをつくるほうが経済的には理にかなっている。それと同じように、犯罪や詐欺の多くも、一種の報酬関数のハッキングと考えることができる。医師でさえ、報酬関数をハッキングすることがある。アメリカでは、優秀な医師を選び、平均よりも手術の生存率が低い医師を避け、医師の技術を向上させるのに、医師の成績表が役立つと考えられている。ところが、成績表に傷がつくのを恐れて、リスクのある手術が必要な患者を門前払いする医師が現われはじめたというのだから本末転倒だ。
しかし、人間はいつも協力的ではないにせよ、ふつうは報酬関数の本来の目的をある程度わかっている。ところがAIにはそういう概念はない。AIは人間をやっつけようとしているわけでも、意図的にずるをしようとしているわけでもない。AIの仮想的な脳はミミズ並みで、幅の狭い作業をいちどにひとつしか学習できないのだ。人間の倫理に関する質問に答えるようAIをトレーニングしたなら、そのAIにできるのはそれだけだ。車を運転することも、顔を認識することも、履歴書を審査することもできないし、物語の倫理的葛藤について理解し、考察することもできない。物語の理解はまったく別の作業なのだ。
2017年12月のカリフォルニア州の山火事の最中、カーナビ・アプリが炎の燃え広がっている地域へと車を誘導したのも、まったく同じ理屈だ。そのアプリは何も人間を焼き殺そうとしていたわけではない。その地域の道が山火事のせいで空いていることに気づいただけだ。山火事が起きているだなんて、だれにも教わっていなかったのだ。
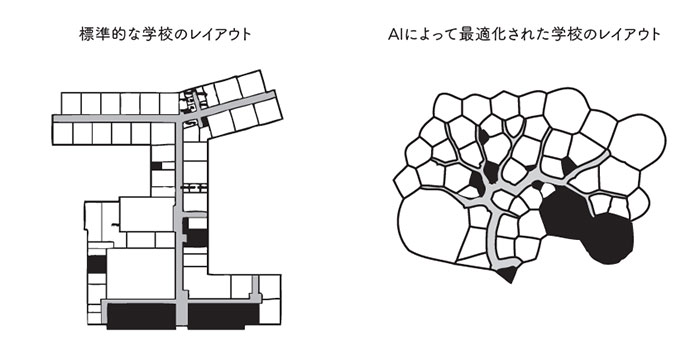
コンピューター科学者のジョエル・サイモンは、遺伝的アルゴリズムを使って、従来よりも効率的な小学校のレイアウトを設計した。最初にできあがった設計では、丸い壁に囲まれた洞窟状の建物の中心部の奥深くに、窓のない教室が埋めこまれていた。これも先ほどと同じ原因によるものだ。だれも窓や火災時の避難計画について教えていなかったし、壁がまっすぐでなければならないとも伝えていなかった。
わたしが再帰型ニューラル・ネットワーク(RNN)に新しいポニーの名前を生成させるトレーニングを行ったときもそうだった。そのRNNはすでに存在するポニーの名前をまねることによって学習していたので、ポニーの名前によく見られる文字の組みあわせはわかっていたけれど、絶対に避けたほうがいい組みあわせは理解していなかった。その結果、こんなポニーの名前を考え出してしまった。
Rade Slime(レード・スライム)
Blue Cuss(青い野郎)
Starlich (星の屍霊)
Derdy Star(お下劣な星)
Pocky Mire(穴だらけの沼)
Raspberry Turd(おなら野郎)
Parpy Stink(おならっぽい悪臭)
Swill Brick (がぶ飲みコカイン)
Colona(コロナ)
Star Sh*tter (星クソ)
人種差別や性差別をするのがデータセット内の人間の行動をまねる手っ取り早い方法だと学んでしまうアルゴリズムがあるのも、同じ理由だ。アルゴリズムは人間のバイアスをまねるのがよくないことだなんて知りもしない。ただ、目標達成に役立つパターンを見つけるだけだ。そこに倫理と常識を補うのはプログラマーの仕事なのだ。

株式会社光文社Copyright (C) Kobunsha Co., Ltd. All Rights Reserved.